Notebooks are a web-based Jupyter IDE with shared persistent storage for long-term development and inter-notebook collaboration, backed by accelerated compute.
Gradient offers two types of storage: Persistent Storage and Versioned Data.
Persistent storage is a high-performance \storage directory located within Notebooks. Persistent storage is backed by a filesystem and is ideal for storing data like images, datasets, model checkpoints, and other resources. Anything you store in the /storage directory is accessible across multiple runs of notebooks in a given storage region.
Gradient provides the ability to mount S3-compatible object storage buckets to workloads at runtime. Datasets have immutable versions which you can use to track your data as it changes. For more information on creating versioned data, see Create Datasets.
Within Gradient, Volumes allow various Gradient resources to access a shared Network File System. Storage volumes provide a block-level storage device as the primary system drive on a Paperspace machine. Volumes appear to the operating system as locally attached storage which you can partition and format as needed.
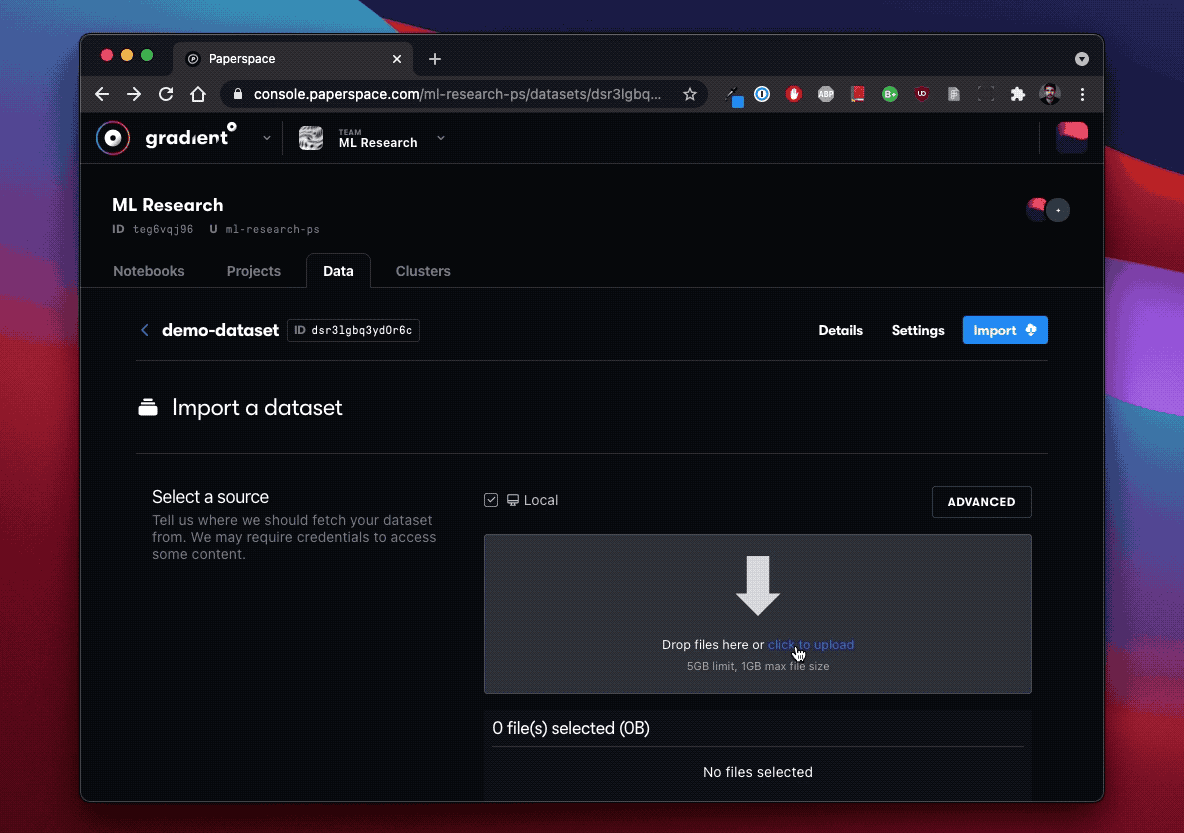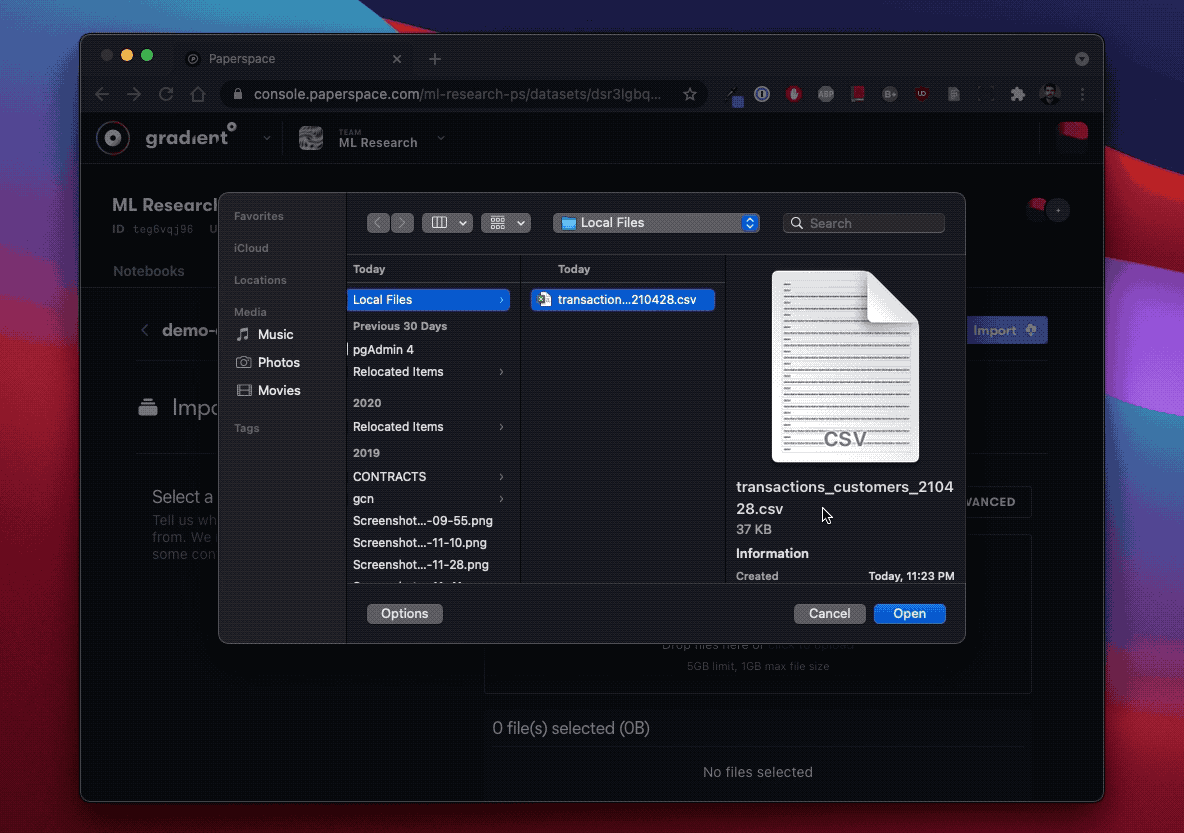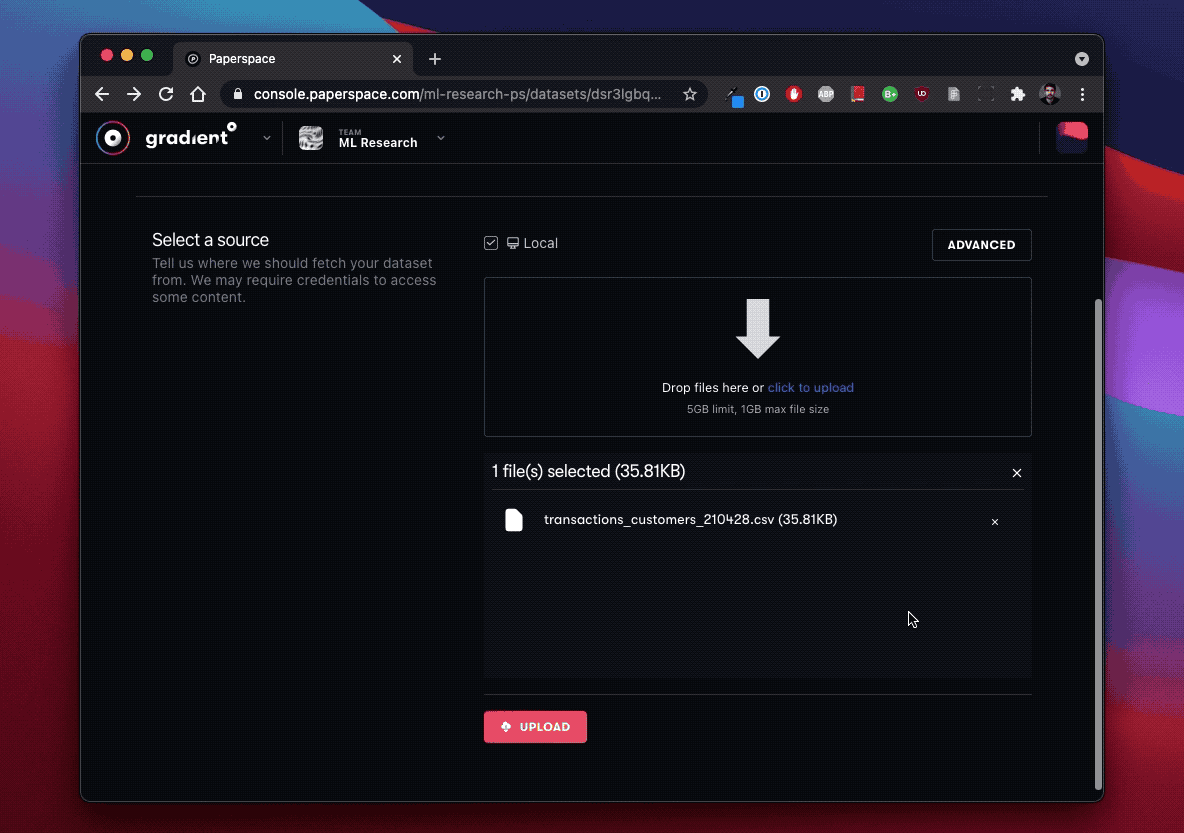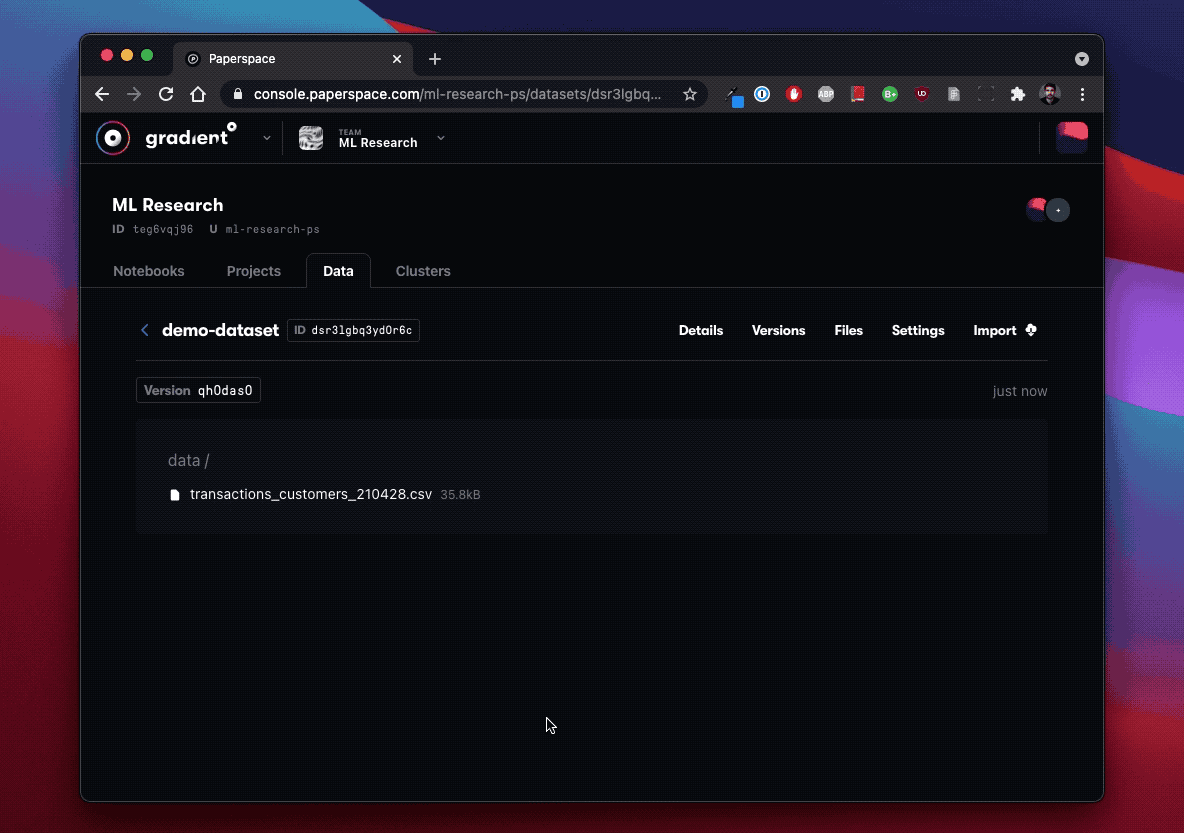
Gradient Versioned Datasets: You can create versioned datasets for storing ML data, artifacts, and models. The data is accessible through one or more job-specific paths you provide. You can create versioned datasets directly using the CLI, in the Data tab in the Paperspace console, or through Workflows that enable regular updates to the file via GitHub. You can store versioned datasets in Gradient Managed, DigitalOcean Spaces Object Storage, or another storage provider.
/storage: This is a team-wide shared storage directory on the NFS or other Kubernetes Container Storage Interface storage option, such as Ceph. This is created and allocated as a Kubernetes PersistentVolume during installation that is accessible.
Gradient Volumes: These are temporary Workflow run volumes that only exist for the duration of the Workflow run. They are referenced under the same root paths as Gradient dataset versions. Use these volumes to instantiate, access, and upload to temporary storage spaces facilitating your Workflow without storing the files/data permanently in one of the persistent storage options.
/notebook: This is a directory under the team’s /storage root that stores the home directory content of each notebook run. You can clone the files in the notebook repository directly from GitHub to efficiently set up your workspace. When creating a new notebook, specify the URL in the URL field of the Workspace section in the Advanced Options section. This is allocated as a temporary sub-volume under the main team storage volume./{team-id}/datasets: This stores cached named versions of the Gradient datasets. Your team can control the size of the cache. Data stored in the cache is automatically backed up to the configured storage provider.metrics: This is a persistent volume where Prometheus metrics data is stored.share-storage: This is a cluster-wide persistent volume that team sub-volumes are allocated.Datasets have multiple versions. You can specify a new dataset version by adding information about the newly-created dataset version. In addition, you can tag a specific dataset version with a custom name. You can reference a dataset in the following ways:
[dataset-id]:latest: Uses the latest version of your dataset[dataset-id]:[dataset-version]: Uses the specified dataset-version[dataset-id]:[dataset-tag] : Uses the specified dataset version that the dataset-tag points toDataset versions have an uncommitted and committed state. When a dataset is uncommitted, you can modify or add files freely. When a dataset is committed, it is immutable and you cannot modify it. This makes the workloads repeatable and deterministic with the provided datasets.